Physical AI is getting smarter. Deployments are getting harder.
That is the uncomfortable pattern emerging across robotics and autonomous machines. A single robot performs well in a controlled environment. Perception is adequate. Policies generalize. The orchestrator behaves. Then the system scales from one machine to many, from a pilot zone to an operational site, from a demo to a shift schedule.
Performance gets fragile.
Throughput plateaus. Coordination becomes erratic. Telemetry develops gaps. Failures arrive in clusters rather than one at a time. The machines are not obviously less intelligent, yet the system behaves as if it has become less coherent.
The bottleneck has moved. Many teams are still looking where it used to be.
The missing specification is connectivity.
That is the argument of a new whitepaper written with Apeiroon, the team behind Roadwave — a family of compact, rapidly deployable private 4G/5G systems for autonomous machines in the field. Cyberwave approaches Physical AI from the software side: digital twins, edge AI runtimes, fleet orchestration, and hardware abstraction. Apeiroon approaches it from the communications side: private mobile infrastructure engineered for machines in motion.
We have been collaborating since early this year. Across deployments, sectors, and geographies, we kept finding the same architectural weakness from opposite directions. So we decided to state it plainly.
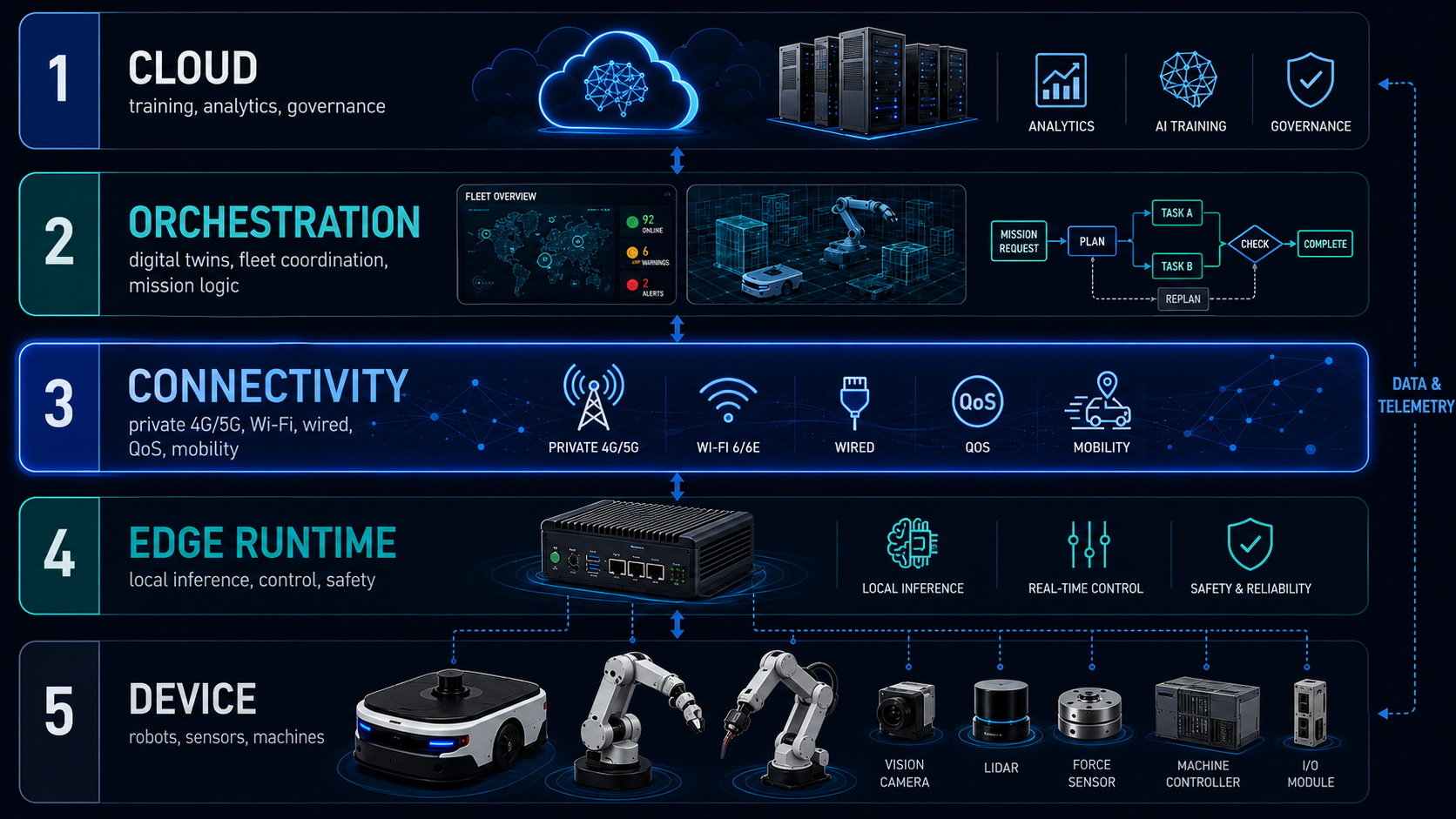
The whitepaper develops that observation through a five-layer Physical AI stack and three deployment configurations that show how inference, control, orchestration, and connectivity can be distributed.
The network is already in your autonomy stack§
Most Physical AI systems carry an implicit communications envelope. It is rarely written down, but it is there.
It appears as default timeouts, retry budgets, assumed update rates, tolerated packet loss, unspoken handover expectations, and optimistic beliefs about uplink capacity. Control logic, orchestration logic, teleoperation, observability, and even inference placement are then designed around these assumptions.
The problem is not that teams ignore connectivity. It is that they often treat it as a utility rather than a system dependency.
That distinction matters.
A utility is expected to be broadly available. A dependency must be specified, measured, and validated. In Physical AI, connectivity is the second.
When the network deviates from the assumptions embedded in the software stack, the symptoms rarely look like “network problems.” They look like robotics problems.
Control loops become less stable. Multi-robot coordination fragments. Operators lose visibility exactly when they need it most. A perception service appears unreliable when the real problem is intermittent uplink. A fleet-management policy looks poorly tuned when the underlying issue is delayed shared state. The post-mortem blames the controller, then the model, then the simulator — and often reaches the network last.
This is not because the network failed in a conventional sense. It may be performing perfectly well as a general-purpose service. The failure lies in the mismatch between a best-effort communications layer and an autonomy stack that quietly depends on stronger guarantees.
Both sides can be “working as designed.” The system still fails.
What the software stack actually requires§
A robot is no longer just a device executing local commands. It participates in an operational graph: shared maps, task queues, teleoperation streams, observability pipelines, edge inference services, and cloud-level analytics.
The relevant question is not whether the robot is connected. It is whether the system can maintain coherence while the robot moves.
That requires more than bandwidth. Latency must be predictable. Jitter must be bounded. Mobility must not break service continuity. Uplink must be engineered as carefully as downlink. Degradation must be visible before it becomes an incident.
These are not network metrics in isolation. They determine whether shared state arrives in time to coordinate a fleet, whether a remote operator can intervene safely, whether edge inference remains usable under congestion, and whether orchestration sees deterioration before it becomes failure.
In other words, connectivity is not adjacent to the autonomy stack. It shapes the conditions under which the autonomy stack remains dependable.
What the network side reveals§
From the connectivity side, the same failure mode appears in reverse.
A deployment starts on enterprise Wi-Fi or public cellular. Initial tests pass. A few robots move reliably. Video streams look acceptable. Telemetry arrives. The pilot is declared healthy.
Then the fleet grows.
Imagine a warehouse operating five autonomous mobile robots during a pilot. Each sends telemetry, occasional video, and state updates to a local control system. The deployment looks stable. Now scale the same environment to fifty robots, with denser task coordination, more frequent perception uploads, and more operator interaction. Handover events begin to matter. Latency distributions widen under load. Coordination appears less reliable, even though the robots themselves have not become worse.
Nothing mystical happened. The workload changed. The network assumptions did not.
Public cellular is valuable. Wi-Fi is valuable. Wired industrial systems remain essential where machines are fixed. But fleets of mobile, sensor-rich machines introduce a different set of requirements. They require a communications layer that can be engineered locally for coverage, service quality, mobility, edge integration, and runtime observability.
That is where private mobile networks become strategically important — not because they are fashionable, but because they make the communications layer engineerable.
The pilot-to-production trap§
The most dangerous part of this problem is that it often stays hidden during pilots.
Pilots are forgiving. Device density is low. Traffic is intermittent. Operators are attentive. Environmental variability is limited. Failures are investigated manually and tolerated socially.
Production is not forgiving.
Production means sustained operation, peak traffic, moving interference sources, overlapping missions, software updates, multiple traffic classes, and machines that must remain observable and safe without a room full of engineers watching dashboards.
This is why connectivity debt accumulates silently. It does not always appear during prototype validation. It appears when the system finally begins to matter.
And by then, the architecture may already be built around assumptions that were never explicitly tested.
The shared conclusion§
Connectivity is the missing specification for Physical AI.
Whether acknowledged or not, the rest of the architecture is already being written against a network contract. The choice is not whether that contract exists. It does. The choice is whether to leave it implicit or make it explicit.
Once made explicit, engineering decisions change.
Throughput becomes only one variable among many. Tail latency matters. Jitter matters. Handover behaviour matters. Degraded-mode semantics matter. Uplink must be sized as carefully as downlink. Edge inference must be placed against real network conditions, not whiteboard optimism. Orchestration should reason about network state, not merely discover disconnection after the fact.
Connectivity stops being a procurement line item. It becomes a design parameter that compute, inference, autonomy, and control are co-designed around.
For many real-world Physical AI deployments, the limiting factor is no longer model capability alone. It is the infrastructure required to make that capability dependable in motion.
What is in the paper§
The whitepaper develops this argument in detail. It examines:
- why best-effort connectivity assumptions fail as autonomous systems scale;
- how intelligence should be distributed across device, edge, connectivity, orchestration, and cloud layers;
- why private mobile networks matter for fleets in motion;
- how deployment architectures change as inference and control move offboard.
The paper is written for engineering leaders, robotics teams, infrastructure architects, and executives who have already discovered that their model is not the only thing standing between a promising pilot and a dependable deployment.