
Reinforcement Learning Meets Digital Twins: Training Robots to Think for Themselves
Teaching a robot to pick up a box sounds simple. Teaching it to pick up any box—regardless of size, weight, or orientation—while adapting to a conveyor belt that never stops? That's a different problem entirely.
Traditional programming approaches fail here. You can't hard-code every possible scenario. You can't anticipate every edge case. But you can let the robot learn from experience.
This is reinforcement learning (RL)—and it's now available in Cyberwave through our Gym environment integration and MuJoCo physics simulation.
What Is Reinforcement Learning?
At its core, reinforcement learning is how machines learn through trial and error. Instead of programming explicit rules, you define:
- The environment — what the robot can see and interact with
- The actions — what the robot can do (move joints, grip objects, navigate)
- The reward signal — what "success" looks like
The robot then explores its environment, tries different actions, and gradually discovers strategies that maximize its reward. It's the same principle behind how children learn to walk or how you learned to ride a bike—except it happens in simulation, millions of times faster.
Why This Matters for Robotics
Traditional robot programming is brittle. A pick-and-place routine that works perfectly for Box A will fail spectacularly when Box B arrives 2 centimeters wider. Engineers spend weeks tuning parameters, writing exception handlers, and praying the production environment matches the test setup.
RL-trained policies are different. They learn to generalize. A robot trained on thousands of box variations in simulation develops intuition—it learns what features matter (grip width, approach angle, object stability) and what doesn't (exact color, lighting conditions, conveyor speed within reasonable bounds).
The result: robots that handle real-world variability without constant reprogramming.
The Sim2Real Challenge
Here's the catch: training in the real world is slow, expensive, and dangerous. You can't crash a robot arm into a conveyor belt 10,000 times to learn what doesn't work.
This is where digital twins become essential.
A digital twin isn't just a 3D model. It's a physics-accurate simulation of your robot, your workspace, and everything in it. When you train an RL policy in a properly configured digital twin, the skills transfer to the real robot—a process called Sim2Real transfer.
The key is fidelity. The simulation must capture the physics that matter:
- Dynamics — how objects move under force
- Contacts — how the gripper interacts with surfaces
- Sensors — what the robot actually perceives
- Noise — real sensors are never perfect
Get these right, and your simulation becomes a training ground. Get them wrong, and you're training for a world that doesn't exist.
How Cyberwave Enables RL Training
Cyberwave now provides an end-to-end pipeline for training RL policies on your digital twins.
1. Build Your Environment in Cyberwave
Start in the Environment Editor—our visual tool for constructing robotic workspaces. Import your robot from the asset library, add objects to manipulate, define the workspace boundaries.
Everything you build is simulation-ready. No XML editing, no mesh debugging, no "works on my machine" surprises.
2. Export to Physics Simulation
With one click, export your environment to MuJoCo—the physics engine trusted by leading robotics research labs. As we covered in our MuJoCo quickstart guide, the workflow is seamless.
Your digital twin now lives in a physics sandbox where you can simulate millions of interactions.
3. Train with Gymnasium Environments
Cyberwave environments are compatible with Gymnasium (the successor to OpenAI Gym)—the standard interface for RL training.
This means you can use any RL library you prefer:
- Stable Baselines3 — production-ready implementations of PPO, SAC, TD3
- skrl — high-performance training with parallel environments
- CleanRL — single-file implementations for research
- Ray RLlib — distributed training at scale
Our demo environments already include reward functions, observation spaces, and action spaces tuned for robotic manipulation tasks.
4. Deploy Trained Policies
Once your policy passes evaluation, deploy it through Cyberwave's Edge SDK. The trained neural network runs on edge compute (NVIDIA Jetson, Intel NUC, or any Linux device), receiving sensor data and outputting motor commands in real time.
Example: Adaptive Packaging with Variable Box Sizes
Let's make this concrete with a use case we're actively developing: adaptive packaging in logistics.
The Problem
A warehouse fulfillment line handles thousands of products daily. Each product has different dimensions, weights, and packaging requirements. Traditional automation requires:
- Custom end-of-arm tooling for different box sizes
- Precise staging areas where boxes must be placed exactly
- Manual intervention whenever a new SKU is introduced
This works for high-volume, low-variety operations. It breaks down when variety increases.
The RL Approach
Instead of programming rules, we train a policy that learns to:
- Perceive the incoming box (size, orientation, position on conveyor)
- Plan an approach trajectory that avoids collisions
- Execute a grip that's stable regardless of exact box dimensions
- Place the box in the optimal position for downstream processing
The training environment includes:

The Reward Function
The reward signal encodes what success looks like:
reward = (
-distance_to_box * 0.1 # Get close to the target
+ grasp_success * 10.0 # Successfully grip the box
+ place_success * 20.0 # Place box in target zone
- collision_penalty * 5.0 # Don't hit anything
- time_penalty * 0.01 # Be efficient
)Through millions of simulated episodes, the policy discovers strategies humans wouldn't think to program—like approaching from unconventional angles when the standard approach is blocked, or adjusting grip force based on inferred box weight.
The Results
After training, the policy handles:
- Novel box sizes not seen in training (within reasonable bounds)
- Perturbed conveyor speeds that vary from episode to episode
- Imprecise initial positioning where boxes aren't perfectly aligned
- Partial occlusion where camera views are partially blocked
This isn't hypothetical. Our UR7 conveyor demo implements exactly this workflow, training PPO policies that achieve >90% success rates on pick-and-place tasks.
Domain Randomization: The Secret to Sim2Real Transfer
The gap between simulation and reality is real. Friction coefficients differ. Sensor readings have bias. Lighting changes throughout the day.
Domain randomization bridges this gap by deliberately varying simulation parameters during training:
- Randomize friction between gripper and object
- Add noise to camera observations
- Vary object textures and colors
- Introduce latency in control loops
- Simulate sensor dropout and degradation
A policy trained on varied conditions learns to extract the features that matter—object geometry, relative positions, dynamics—while ignoring the features that vary—exact colors, precise friction, lighting conditions.
The result: policies that transfer more reliably from simulation to reality because they've never been able to rely on simulation-specific shortcuts.
When to Use RL vs. Traditional Approaches
RL isn't always the answer. Here's a practical framework:
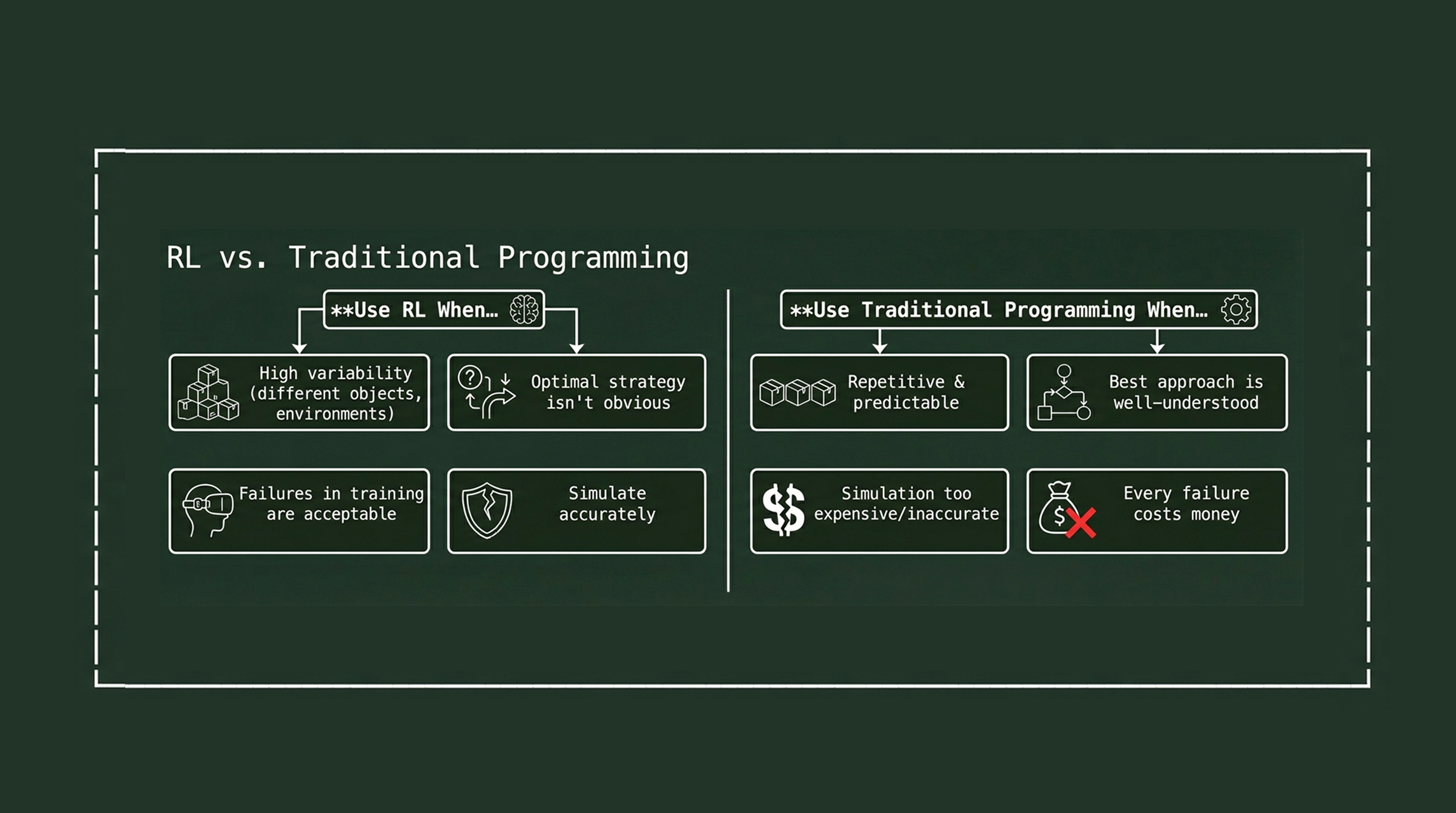
For the packaging example, RL makes sense because the variability is high and simulation is accurate. For a task like "move joint 3 to exactly 45 degrees," traditional control is simpler and more reliable.
Getting Started with RL on Cyberwave
Ready to train your first RL policy? Here's your path:
1. Build Your Environment
Use the Cyberwave editor to construct your workspace. Import your robot from our asset library, add the objects you want to manipulate, and export to MuJoCo.
2. Define Your Gym Environment
Wrap your MuJoCo scene in a Gymnasium environment. Our demo environments provide templates for common manipulation tasks.
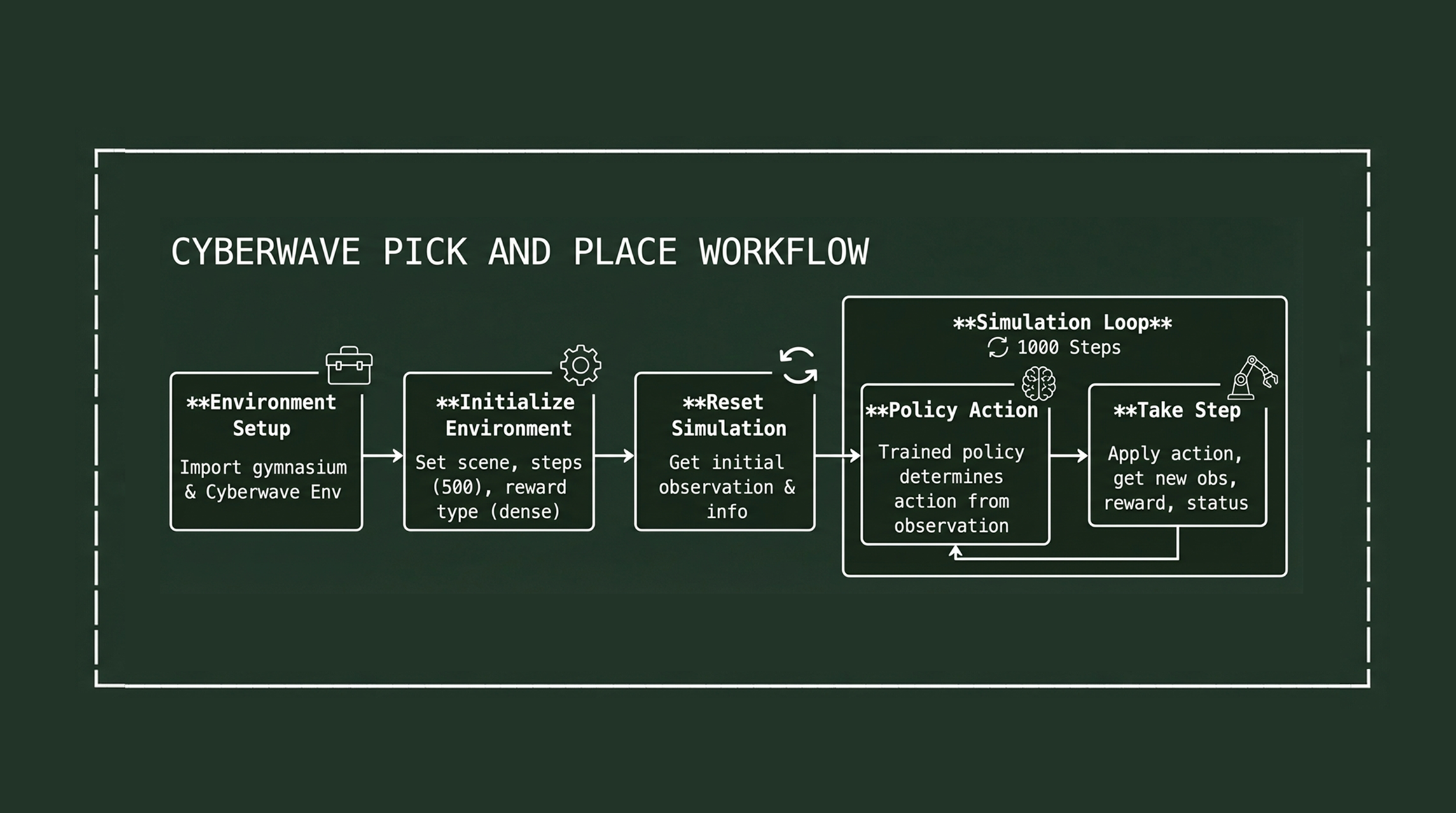
3. Train Your Policy
Use your preferred RL library. We recommend starting with PPO (Proximal Policy Optimization) for its stability and good performance across tasks.
from stable_baselines3 import PPO
model = PPO("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=1_000_000)
model.save("pick_and_place_policy")4. Evaluate and Deploy
Run your trained policy through evaluation scenarios. When it passes, deploy via our Edge SDK to your physical robot.
The Bigger Picture: Autonomy That Ships
RL training is one piece of Cyberwave's Sim2Real autonomy pipeline. The full workflow includes:
- Simulation-first training — train at scale without risking hardware
- Evaluation & regression — systematic testing before deployment
- Safety gates — constrain outputs and enforce limits
- Traceable deployments — audit, reproduce, and roll back with confidence
This isn't about replacing human operators. It's about giving robots the flexibility to handle the variability that currently requires constant human intervention.
The factories and warehouses that win the next decade will be the ones that can reconfigure on the fly. RL-trained policies—developed in simulation, validated systematically, deployed with safety constraints—are how we get there.
Join the Builders Program
We're actively developing RL capabilities with our Builders Program community. If you're working on manipulation tasks, navigation, or any application where learned policies could outperform hand-coded rules, we want to hear from you.
Join our Discord to connect with builders already training policies on Cyberwave.
Request early access to get started with your own RL experiments.
The future of industrial automation isn't about smarter robots. It's about robots that can learn—and platforms that make that learning practical. That's what we're building.